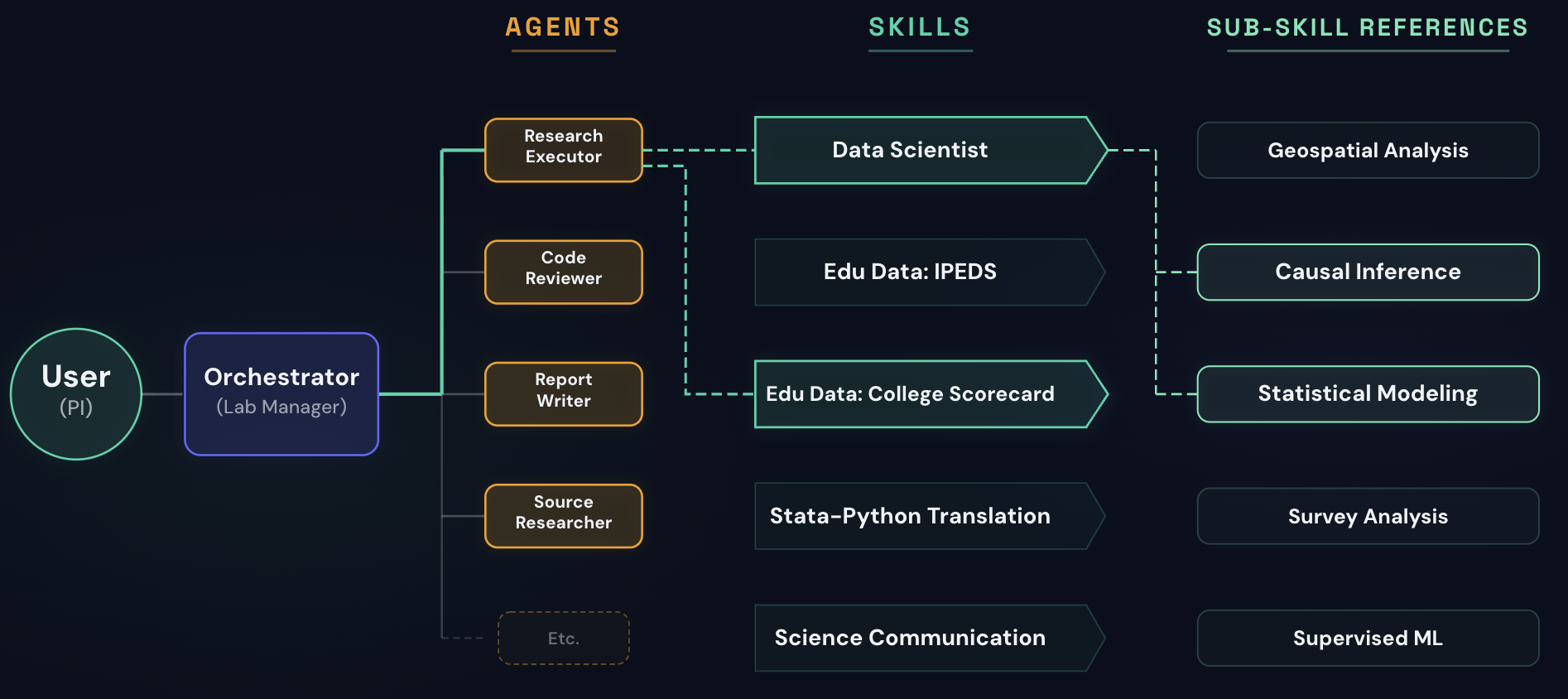
Powerful AI tools are increasingly available to the public -- but the organizations doing the most important public-interest work often have the least capacity to evaluate, adopt, and integrate these tools responsibly. Open Augments exists to close that gap: we partner with expert practitioners to build rigorous, open-source AI tools that enhance and transform their core public-interest work, and we provide hands-on training and strategic consultation that gives researchers and organizations the skills and confidence to harness AI on their own terms, with human expertise always leading the way.
We are a mission-driven organization,
guided by the conviction that both the tools and the know-how for conducting responsible,
AI-augmented work should be widely available to anyone who
would use them to help others. That in mind, we are committed to ensuring every tool is honed in close collaboration with real practitioner experts, every framework we create is open-source, and every educational resource is freely shared.
Open Source, Always
The infrastructure to harness AI responsibly and effectively should be a public good for the benefit of all, not a competitive advantage.
Augmentation, Not Replacement
We build tools and teach approaches that use AI to amplify and enhance what skilled and caring individuals can do. Every framework and lesson keeps expert humans central to the strategy, oversight, and decision-making where it counts.
Rigor & Transparency First
AI-empowered work must always be accountable to the people it serves. Our non-negotiables: AI outputs must be auditable and reproducible, and every limitation must be honestly acknowledged.